COBRA-performance: Theory versus Reality
COBRA-performance: Theory versus Reality
Michael Kramer
Introduction
In order to select the best processor type for COBRA, we had designed two
benchmark tests, both based on Princeton MkIV code that will be in parts
utilised in COBRA. Most of all comparisons have been carried out using
Version 7 (``disk7'').
The first part of the benchmark performs forward Fast-Fourier
Transforms (on two arrays),
resulting in an efficiency
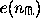 measured in MSamples/sec
(test 1). The second test performs the full de-dispersion code, including the
chirp function and folding (test 2). Here, the benchmark result is a ratio of
computation to observing time,
measured in MSamples/sec
(test 1). The second test performs the full de-dispersion code, including the
chirp function and folding (test 2). Here, the benchmark result is a ratio of
computation to observing time,
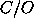 as a function of dispersion measure,
as a function of dispersion measure,
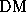 (which translates to
(which translates to
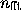 ).
).
In the following, we will assume that it is the FFT which is dominating
the computation time. As will later see, that is not completely true. All
calculations will be done for a sky frequency of 1400 MHz.
Theory
The time over which de-dispersion has to be performed is assumed
to be twice the smearing time, $\Delta t$,
across the band, $\bw$. We will call
this time the observing time, i.e.
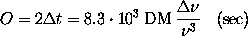
where both bandwidth and centre frequency are measured in MHz. The bandwidth
is the bandwidth {\em processed by a single processor at a single instant}.
Assuming a centre frequency of 1400 MHz, we can reduce that to
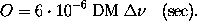
We assume complex sampling and express the sampling time as
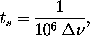
where the time is measured in seconds and bandwidth
in MHz. The number of samples per FFT is then given by
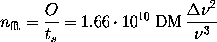
which for 1400 MHz reduces to
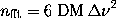
According to theory, the computation time for the FFTs should scale as
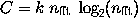
where k is the scaling constant which we expect to be of the order of
1/clockspeed of the processor as we will need a few clock cycles per
array element. Using Eqn.~(\ref{nfft}), we obtain:
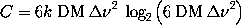
The ratio of compute to observe time is then
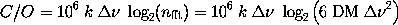
One can view this as a linear increase with bandwidth, where the slope
is a relatively
weak function of DM and bandwidth. In reality this is not true but we
except discrete jumps in the performance when the FFT size exceeds the cache
size.
The number of processors needed
for a total of 100 MHz of bandwidth is given by
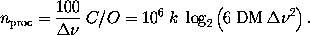
and should only be weakly affected by the bandwidth that we feed to each
processor. However, due to the different performance using cache and main
memory, that will not be true in reality. As we will see, a comparison with
reality will force us to modify Eqns.~(\ref{co}) and (\ref{num}) by another
scaling factor, $A$, which takes into account overheads, additional backwards
transforms and the contributions from chirp and folding:
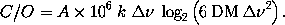
and
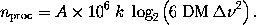
We do not expect the factor $A$ to be a pure constant as folding and chirp
also depend on $\nfft$. As we will see, however, the variety is in fact modest
for the in-cache and out-cache regions of the parameter space. Nevertheless,
we will calibrate $A$ as a function of $\nfft$, which will allow us to scale
$\nproc$ for a various bandwidths but {\em fixed} FFT length (i.e. different
DMs though, see later).
We can summarize the various scaling laws in Table 1. Using
algorithms which perform FFTs only on powers of 2, we introduce discrete jumps
in these relationships. This not strictly necessary anymore using FFTW and
should be explored to make the performance more efficient in such cases
when $\nfft$ just exceeds a $2^m$-boundary. These jumps have been included
in Figures 1 and 2, which also summarize the various
dependencies.
Table 1: Scaling laws for various quantities assuming
a centre frequency of 1400 MHz. Bandwidths are measured in MHz, times in
seconds. Note that in reality
some scaling laws are only valid for parts of the parameter space.
Figure 1. The scaling laws as function of bandwidth processed by a single
processor at a single instant for various dispersion measures.
Figure 2. The scaling laws as function of dispersion measure for various
bandwidths processed by a single processor at a single instant.
Reality
We have already accounted for possible differences to the real-world behaviour
by introducing the factor $A$. Also the scale factor $k$ originating in
Eqn.~(\ref{comp}) needs to be calibrated. We will do this here and compare
our expected behaviour with the test results for two processors, which we
will abbreviate here with $J$ and $D$.
While $J$ is an Swinburne Athlon processor (Jocelyn), $D$ is Pentium-III (833
MHz, fast 1 GB RAM-bus). We hence expect $J$ to be dominant for short,
and $D$ for long FFTs.
In turns out that the graphs obtained from the benchmarking
as a whole do not follow the simple scaling
laws as other factors as cache size are dominating.
However, in various
smaller regions of the parameter space they are followed as expected.
Figure 3. Test results (top: test 1, bottom: test 2) for
both $J$ and $D$, each processing 1.25 MHz bandwidth.
In Figure 3 we present the test results for $J$ and $D$. The efficiency
measured in test 1 (top of figure) clearly shows the transition where
$\nfft$ exceeds the cache size. As expected, this is more prominent for
$J$ which does not have a wide RAM-bus.
The efficiency $e$ measured in test 1 can be written as
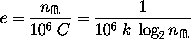
in units of $10^6$ samples\footnote{
The benchmarking code actually uses $1024\times1024=1.05\cdot 10^6$ samples,
Hence, we introduce here an error of 5\% which will however be absorbed in
our scaling.
}, where we used Eqn.~(\ref{comp}). Using the
results from test 1 we can therefore calibrate $k$. Inspecting the
plots one notices that the expected scaling is only valid for more
than $10^4$ samples. While for this region $D$ can be fitted by a single
$k$,
\[ k_D=3.42\cdot10^{-8} ({\rm s}) = 1/(29{\rm MHz}),
\]
we need two different $k$'s for $J$:
\[
k_J(\nfft=2^{14} - 2^{17})=4.0 \cdot 10^{-8} ({\rm s}) = 1/ (25 {\rm MHz})
\]
and
\[
k_J(\nfft=2^{18} - 2^{20})=6.5 \cdot 10^{-8} ({\rm s}) =1/ (15 {\rm MHz})
\]
It is comforting to see that $1/k$ is indeed of the order of the clock
speed.
Knowing k via e we can also calculate the theoretical C/O. Using
Eqn.~(\ref{co2}) and (\ref{eff}) solved for $k$, we simply obtain:
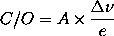
This is a very simple relationship which gives a direct relationship
between the measured efficiency and the compute-to-observed ratio for
a given bandwidth. It is important to note, however, that $e$ is a function
of $\nfft$ obviously, and hence C/O does not directly scale with $\bw$,
as it was already discussed in context of Eqn.~(\ref{co}). However,
having measured $e$, we can easily calibrate the factor $A$ by
comparing the theoretical C/O with what is actually measured in test 2.
The comparisons of theoretical values with measured ones are given
for J in Table 2 and D in Table 3.
Table 2: Comparison of theoretical and measured compute
to observed ration for $J$. Column 1 gives the number of samples, column 2
the corresponding DM for 1.25 MHz bandwidth, the third column is the
theoretical C/O based on test 1 results, column 4 list the values
actually measured with test 2. The overhead factor $A$ is given
in column 5. The last column is the number of processors needed for
100 MHz, using the calibration factor $A$.}
Table 3: Comparison of theoretical and measured compute
to observed ration for D. Columns as in table for J.
Due to the power of two requirement assumed
for the FFT, the same $\nfft$ appears
sometimes for several DMs. The value of $A$ obviously depends
not only on $\nfft$ but also on overlap etc. Typical values for $A$
seem to be between 3 and 5.\footnote{This is also indicated by
looking at results for other processors}
We can use the actual values to calculate now accurately
the number of processors needed to process
100 MHz. The result is presented
in Figure 4. For 1.25 MHz, where the transforms are small,
one would, as expected, choose $J$. Knowing all the quantities we can
now also predict the performance for de-dispersing a chunk of 10 MHz
at a single instant by a single processor. We do this by using
a given value of $\nfft$ to estimate a corresponding DM for a 10-MHz
bandwidth (ignoring powers of 2 boundaries). The results are shown
for $J$ and $D$. As the transforms now become longer, one would
go for $D$, as expected.
Figure 4. Number of processors of type $J$ and $D$ needed
to process a total of 100 MHz for a given bandwidth. The calculation is
done assuming that the total bandwidth is split into chunks
of 1.25 and 10 MHz, respectively.
Summary
The test results can be understood in terms of the theoretical background.
Although the curves do not follow the expected trend as a whole, essential
parts can be understood. For quantitative conclusions one has to assume that
an additional factor $A$ of 3--5 has to be added to the theoretical compute to
observed ratio. It appears that the actual value of $A$ is more or less
independent on architecture. Using this scaling factor and the measured
efficiency $e$, one can safely calculate the C/O ratio for a particular
(instantaneous) bandwidth, using
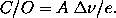
Comparing the k-values for J and D for the largest $\nfft$ is difficult
since we are dealing with different processor types. Results for processors of a given type however indicate that processor speed alone
is not the dominating factor.
It is hence bold to assume that
C/O may really scale with clock speed, but Fig. 4 gives hope that
160 processors running at 1.4-GHz may just do de-dispersing in 10-MHz chunks.
Benchmarks on Pentium IV are also essential. It seems certainly
a promising way
to indeed do a short FFT first in order to produce a slightly coarser data
stream, which then should be relatively easy to process. This relates to the
question about designing a ``score''-program. Figure 4 shows that
presently it is essential to know whether 1.25 or 10 MHz chunks should be
processed.
In any case, there is also room for improvement in the present scheme: The
final result depends linearly on $A$ which most likely can be reduced by
improving the code. This may be in fact the easiest way to enhance the
performance. It also appears that an attempt to incooperate non power-of-two
FFTs will be necessary to ensure a smooth performance curve. The latter
aspect may be in particular interesting when looking at the efficiencies
of the codes: at the moment, we take the next largest power of two as needed
perform the calculations. It is often more efficient to increase the length
of an individual FFT relative to the ``wing'' size. That will however also
depend on the performance of the switch, i.e. the balance between processor
and switch speed. Test with the real system will be necessary.
This document was generated by Pulsar on November 15, 2001